几周前面试遇到一道题:在一个预约业务里,展示顾客复购的情况,是典型的在几张业务表上聚合信息的需求。
用 SQL 可以很方便统计出我们需要的数据,但每次查询都要扫全表性能很差,加缓存又担心维护成本高。 对于比较固定的统计需求,物化视图(Materialized View)是一个低成本的方案。 它是指预计算结果到一张新表,缩短读路径,提高查询性能。
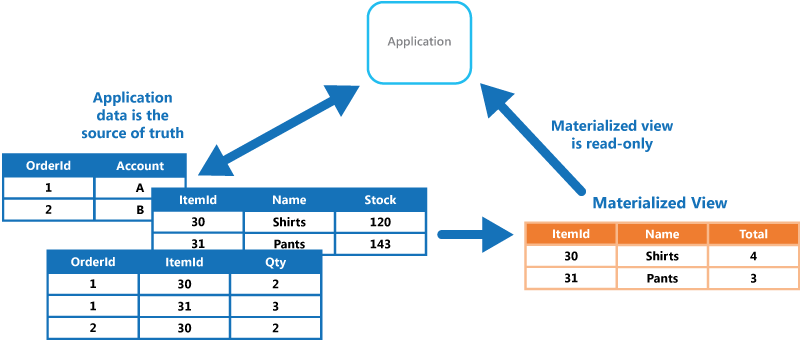
数据库的物化视图
有些传统数据库会提供物化视图功能,例如 PostgreSQL Materialized Views。但通常无法实时更新,例如 PostgreSQL 的 Materialized Views 要用户用REFRESH更新,不能自动增量更新。
前几年兴起的流数据库可以轻松解决这个问题,例如RisingWave介绍里的第一句就是:
RisingWave specializes in providing incrementally updated, consistent materialized views
流数据库无法代替传统的关系型数据库,要单独部署,目前普及程度很低。 在流数据库兴起之前,还有用流处理框架(例如 Apache Flink) 实现物化视图这个选择。
流处理实现物化视图
流数据库和流处理框架实现物化视图的原理是一样的,都是监听数据库的变化(Change Data Capture(CDC)),经过数据转换、连接和聚合,再把结果写进存储服务。
下面用 Flink SQL 实现上文说的面试题,代码放在Github 仓库。
题目介绍
首先有三张已经存在的业务表,分别是顾客表、预约表、顾客预约习惯表:
CREATE TABLE `customer_tab` (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(256) NOT NULL,
last_name VARCHAR(256) NOT NULL
);
CREATE TABLE `order_tab` (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
customer_id BIGINT NOT NULL,
order_time BIGINT NOT NULL,
create_time BIGINT NOT NULL
);
CREATE TABLE `customer_preference_tab` (
customer_id BIGINT PRIMARY KEY,
frequency INT NOT NULL COMMENT 'days'
);
需求是
- 展示每个顾客的预约单总数,最后的预约时间,以及猜测下次预约的时间。
- 所有字段可过滤,需分页展示。
生产中为了高效过滤,通常会把结果保存到 ElaticSearch 里。
为了演示方便我们把结果放到数据库表 customer_reorder_tab :
CREATE TABLE `customer_reorder_tab` (
customer_id BIGINT PRIMARY KEY,
first_name VARCHAR(256) NOT NULL DEFAULT '',
last_name VARCHAR(256) NOT NULL DEFAULT '',
order_count INT NOT NULL DEFAULT '0',
last_order_time BIGINT NOT NULL DEFAULT '0',
expected_next_order_time BIGINT NOT NULL DEFAULT '0'
);
用 Flink SQL 实现物化视图
读取表数据
MySQL CDC Connector 能把 MySQL 表引入 Flink 作为数据来源(Source)。 我们先映射三张业务表到 Flink 里作为 Source:
TableEnvironment env = TableEnvironment.create(EnvironmentSettings.newInstance().inStreamingMode().build());
env.getConfig().getConfiguration().setString("execution.checkpointing.interval", "3s");
val cdcOptSQL = String.format(
"WITH ('connector'='mysql-cdc', 'hostname'='%s', 'port'='%d','username'='%s', 'password'='%s', 'database-name'='%s', 'table-name'='%%s', 'server-id'='%%d')",
mysqlHost, mysqlPort, mysqlUser, mysqlPassword, mysqlDb);
env.executeSql(
"CREATE TEMPORARY TABLE customer_tab (id BIGINT, first_name STRING, last_name STRING, PRIMARY KEY(id) NOT ENFORCED) "
+ String.format(cdcOptSQL, "customer_tab", 5401));
env.executeSql(
"CREATE TEMPORARY TABLE order_tab (id BIGINT, customer_id BIGINT, order_time BIGINT, create_time BIGINT, PRIMARY KEY(id) NOT ENFORCED) "
+ String.format(cdcOptSQL, "order_tab", 5402));
env.executeSql(
"CREATE TEMPORARY TABLE customer_preference_tab (customer_id BIGINT, frequency INT, PRIMARY KEY(customer_id) NOT ENFORCED) "
+ String.format(cdcOptSQL, "customer_preference_tab", 5403));
除了连接配置和列类型,表定义跟 MySQL 几乎是一样的。
写入表数据
JDBC SQL Connector 能让我们把 MySQL 表作为 Flink 的输出(Sink)。 我们把结果表 customer_reorder_tab 作为 Sink :
env.executeSql(
"CREATE TEMPORARY TABLE customer_reorder_tab (customer_id BIGINT, first_name STRING, last_name STRING, order_count INT, last_order_time BIGINT, expected_next_order_time BIGINT, PRIMARY KEY(customer_id) NOT ENFORCED) "
+ String.format(
"WITH ('connector'='jdbc', 'url'='jdbc:mysql://%s:%d/%s', 'table-name' = 'customer_reorder_tab', 'username' = '%s', 'password' = '%s')",
mysqlHost, mysqlPort, mysqlDb, mysqlUser, mysqlPassword));
聚合计算
到了核心的统计逻辑,我们用 JOIN 连接三个表,按 customer_id 分组(GROUP BY)聚合出结果,并更新(INSERT INTO)到customer_reorder_tab表
env.executeSql(
"INSERT INTO customer_reorder_tab \n" +
"SELECT c.id, FIRST_VALUE(c.first_name), FIRST_VALUE(c.last_name), CAST(COUNT(o.id) AS INT)\n" +
", IFNULL(MAX(o.order_time),0)\n" +
", IFNULL(MAX(o.order_time) + NULLIF(FIRST_VALUE(cp.frequency),0) * 24 * 3600000, 0) \n" +
"FROM customer_tab AS c \n" +
"LEFT OUTER JOIN order_tab AS o ON c.id = o.customer_id \n" +
"LEFT OUTER JOIN customer_preference_tab AS cp ON c.id = cp.customer_id \n" +
"GROUP BY c.id");
非常简短的 SQL。看一下测试结果:
...
Day 34
new customer count: 85, new order count: 320
after waiting 3s, mismatch count: 0
Day 35
new customer count: 1, new order count: 276
after waiting 3s, mismatch count: 0
Day 36
new customer count: 84, new order count: 338
after waiting 3s, mismatch count: 0
Day 37
new customer count: 62, new order count: 370
after waiting 3s, mismatch count: 0
Day 38
new customer count: 40, new order count: 285
after waiting 3s, mismatch count: 0
...
没问题。再看看拓扑图:
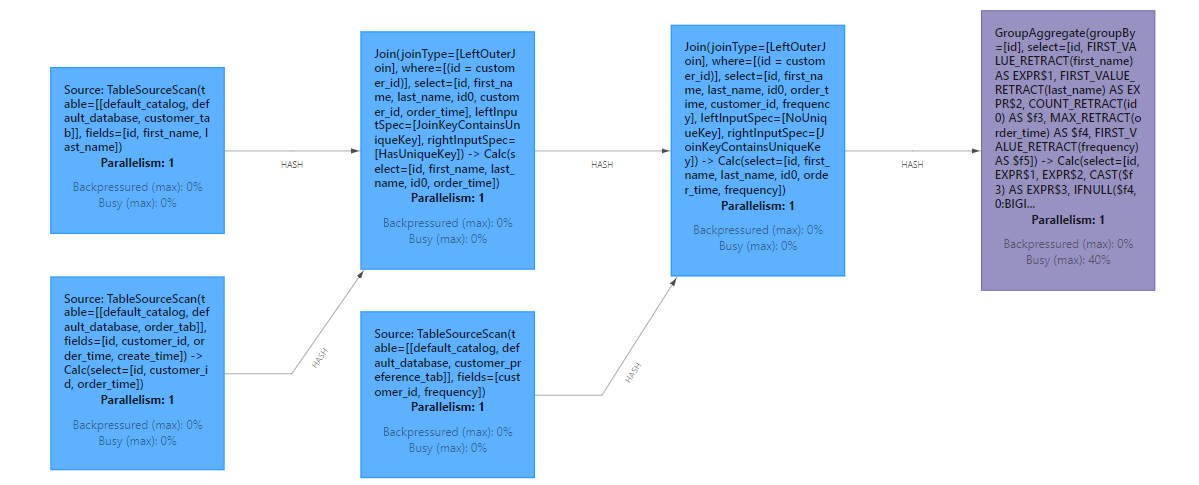
直观的体现出 SQL 的两个 Join。
如标题所说,几行 SQL 就实现了物化视图。
用 Flink DataStream 理解流处理
文章本该到这里结束,以体现 Flink SQL 的简洁和强大,但 Flink SQL 抽象程度太高,第一次接触流处理的人大概率不明白它是怎么工作的。 我们可以用 Flink DataStream API 重新实现一遍物化视图,理解它的工作原理。
DataStream 是 Flink 开始就提供的编程模型,它提供了很多函数式编程的接口,例如 map、filter、keyBy、reduce 等,可以组合成一个实时数据处理的拓扑图。
解析 MySQL 事件
依旧先引入 Source
val env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(3000);
val mySqlSource = MySqlSource.<Change>builder()
.hostname(mysqlHost)
.port(mysqlPort)
.databaseList(mysqlDb)
.tableList("demo.customer_tab", "demo.order_tab", "demo.customer_preference_tab")
.username(mysqlUser)
.password(mysqlPassword)
.deserializer(new ChangeDeserializer())
.build();
val src = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Customer Source");
MySqlSource 可以让我们把过于灵活的SourceRecord转换成我们期望的结构Change,我们根据表做转换,并且为了方便不考虑删除事件:
public class ChangeDeserializer implements DebeziumDeserializationSchema<Change> {
// ...
@Override
public void deserialize(SourceRecord record, Collector<Change> out) throws Exception {
val payload = ((Struct) record.value());
val table = payload.getStruct("source").getString("table");
val newValue = payload.getStruct("after");
if (newValue == null) {
return;
}
boolean create = false;
switch (payload.getString("op")) {
case "c":
case "r": // snapshot read
create = true;
break;
}
val changeBuilder = Change.builder().create(create);
try {
switch (table) {
case "customer_tab":
changeBuilder.customer(new Customer(newValue.getInt64("id"), newValue.getString("first_name"),
newValue.getString("last_name")));
break;
case "order_tab":
changeBuilder.order(new Order(newValue.getInt64("id"), newValue.getInt64("customer_id"),
newValue.getInt64("order_time"), newValue.getInt64("create_time")));
break;
case "customer_preference_tab":
changeBuilder.customerPreference(new CustomerPreference(newValue.getInt64("customer_id"),
newValue.getInt32("frequency")));
break;
default:
throw new IllegalArgumentException(String.format("Unknown table %s, payload: %s", table, payload));
}
} catch (DataException e) {
throw new DataException(String.format("Failed to deserialize payload: %s", payload), e);
}
out.collect(changeBuilder.build());
}
}
自定义拓扑
Flink SQL 生成的拓扑有些复杂了:
customer_tab的数据可以直接写到customer_reorder_tab,统计字段可以初始化为 0order_tab和customer_preference_tab都有customer_id,不需要 JOINcustomer_tab,可以自己算。
用 DataStream 我们可以简化这个拓扑结构。
先把 customer_tab 的变更事件单独拎出来:
val customerTag = new OutputTag<Customer>("customer") { };
val mainStream = src.process(new ProcessFunction<Change, Change>() {
private static final long serialVersionUID = 1L;
@Override
public void processElement(Change value, ProcessFunction<Change, Change>.Context ctx,
Collector<Change> out)
throws Exception {
if (value.getCustomer() != null) {
ctx.output(customerTag, value.getCustomer());
} else {
out.collect(value);
}
}
});
遇到新增和修改就同步到customer_reorder_tab:
val jdbcConnOpts = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(String.format("jdbc:mysql://%s:%d/%s?useServerPrepStmts=false&rewriteBatchedStatements=true",
mysqlHost, mysqlPort, mysqlDb))
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername(mysqlUser)
.withPassword(mysqlPassword)
.build();
mainStream.getSideOutput(customerTag).addSink(JdbcSink.sink(
"INSERT INTO customer_reorder_tab (customer_id, first_name, last_name) VALUES (?, ?, ?) ON DUPLICATE KEY UPDATE first_name=VALUES(first_name), last_name=VALUES(last_name)",
(statement, customer) -> {
statement.setLong(1, customer.getId());
statement.setString(2, customer.getFirstName());
statement.setString(3, customer.getLastName());
},
JdbcExecutionOptions.builder().withBatchIntervalMs(200).build(), jdbcConnOpts))
.name("MySQL Customer Sink");
接下来我们将order_tab和customer_preference_tab的变更根据customer_id分组,每遇到一个变更就更新一下customer_reorder_tab:
mainStream.keyBy(c -> {
if (c.getOrder() != null) {
return c.getOrder().getCustomerId();
} else if (c.getCustomerPreference() != null) {
return c.getCustomerPreference().getCustomerId();
} else {
throw new IllegalArgumentException(String.format("Unknown change type: %s", c));
}
}).map(new ReorderCalc()).name("Calculate reorder info").addSink(
JdbcSink.sink(
"INSERT INTO customer_reorder_tab (customer_id, order_count, last_order_time, expected_next_order_time) VALUES (?, ?, ?, ?) ON DUPLICATE KEY UPDATE order_count=VALUES(order_count), last_order_time=VALUES(last_order_time), expected_next_order_time=VALUES(expected_next_order_time)",
(statement, reorder) -> {
statement.setLong(1, reorder.getCustomerId());
statement.setInt(2, reorder.getOrderCount());
statement.setLong(3, reorder.getLastOrderTime());
statement.setLong(4, reorder.getExpectedNextOrderTime());
},
JdbcExecutionOptions.builder().withBatchIntervalMs(200).build(), jdbcConnOpts))
.name("MySQL ReorderInfo Sink");
算子的中间状态
上面我们使用了一个 ReorderCalc 算子,它可以理解成对 Change 的 reduce 。
回顾函数式编程里 reduce 的定义,它每次会给合并函数一个累计值和一个新元素。 在 Flink 里,累计值是算子的状态(State),会被定期持久化(Checkpoint),用于重启和故障恢复。
在 ReorderCalc 里,我们用 ReorderState 类表示算子的状态,它包含三个字段:
OrderCount:预约单总数LastOrderTime:最后的预约时间Frequency:预约习惯
合并函数只需做一些递增、比较和取最大值的操作:
public class ReorderCalc extends RichMapFunction<Change, ReorderInfo> {
// ...
private transient AggregatingState<Change, ReorderState> reorderState;
@Override
public void open(Configuration parameters) throws Exception {
AggregatingStateDescriptor<Change, ReorderState, ReorderState> descriptor = new AggregatingStateDescriptor<>(
"reorder",
new AggregateFunction<Change, ReorderState, ReorderState>() {
@Override
public ReorderState createAccumulator() {
return new ReorderState(0, 0, 0);
}
@Override
public ReorderState add(Change value, ReorderState accumulator) {
if (value.getOrder() != null) {
return new ReorderState(
accumulator.getOrderCount() + (value.isCreate() ? 1 : 0),
Math.max(accumulator.getLastOrderTime(), value.getOrder().getOrderTime()),
accumulator.getFrequency());
} else {
return new ReorderState(
accumulator.getOrderCount(),
accumulator.getLastOrderTime(),
value.getCustomerPreference().getFrequency());
}
}
//...
}, TypeInformation.of(ReorderState.class));
this.reorderState = this.getRuntimeContext().getAggregatingState(descriptor);
}
@Override
public ReorderInfo map(Change value) throws Exception {
this.reorderState.add(value);
val state = this.reorderState.get();
long customerId;
if (value.getOrder() != null) {
customerId = value.getOrder().getCustomerId();
} else {
customerId = value.getCustomerPreference().getCustomerId();
}
long expectedNextOrderTime = 0;
if (state.getFrequency() > 0 && state.getLastOrderTime() > 0) {
expectedNextOrderTime = state.getLastOrderTime() + state.getFrequency() * DAY_IN_MILLIS;
}
return new ReorderInfo(customerId, state.getOrderCount(), state.getLastOrderTime(), expectedNextOrderTime);
}
}
成果
下面是用 DataStream 实现的拓扑图:
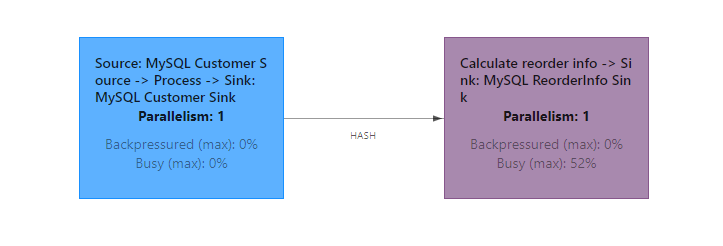
拓扑图变得很简单,因为 Flink 会合并 Trivial 的步骤,只有分组操作 keyBy 增加了一个节点。
工程问题
Flink SQL 这么简洁,这个解决方案可以在生产环境上用吗?
门槛有些高,主要有两个问题:
- 运维成本高:Flink 以集群方式部署,如果实现一个物化视图需要部署好几个服务,大概率会引入新的问题。

- 学习/维护成本高:Flink 作为一个通用、高可用、强一致性的流处理框架,复杂度很高。
流数据库为了降低使用成本,把计算和存储闭环在一个系统里。 期待它能将简洁强大的流处理技术普及起来。