之前在电商公司做商品发货的业务,我们后台管理系统里订单查询页面,需要支持灵活、丰富的筛选条件,比如筛选出供应商 X 昨天发货的话费充值订单,还要按创建时间倒序分页。
有哪些解决方案?
数据库 B 树索引
直接查数据库,是最简单的实现方式。
通常在一些使用频繁、区分度高的字段上建立索引,就可以满足查询的性能要求。
最常用的数据库索引是 B 树索引,它的顺序存储结构使它能高效地支持范围查询和排序。
但是,如果筛选条件是多个属性的组合,那受限于最左匹配原则,一个B 树多列索引无法覆盖所有组合。
例如给订单表 orders 加一个(provider_id,order_status,create_time)的多列索引,它能加速指定供应商、指定状态、按时间排序的查询,但它无法用于缺少供应商 ID 或订单状态的查询。
1
2
3
4
5
6
|
select * from orders where provider_id = ? and order_status = ? order by create_time desc;
select * from orders where provider_id = ? order by create_time desc;
select * from orders where order_status = ? order by create_time desc;
select * from orders order by create_time desc;
|
为了支持各种组合的筛选条件和排序,需要建立大量的索引,这会大幅降低写入性能。
或是折中一下,凭经验建立少量索引,但是会有一些查询效率很低的情况,影响用户体验,也会造成数据库负载过高。
ElasticSearch 的倒排索引
ElasticSearch 很适合这种查询条件灵活、对性能要求高的场景,有很多成熟的方案。
这次我们绕过 ElasticSearch,来看看它背后的引擎——倒排索引。
倒排索引
倒排索引可以理解为是一个索引键到文档列表的映射,简略地说,就是一个哈希表。
它的特别之处在于映射值是一个文档 ID 列表,称为倒排列表(Postings list)。

Postings list 有很好的压缩效果,还可以互相组合,实现复杂的查询。
组合复杂查询
假设我们有一个状态到订单 ID 的哈希表 map[Status][]ID ,想找出已完成和已退货的订单,可以怎么做?
很简单,取两个状态的订单 ID 列表的并集就行了。
再比如,还有一个供应商 ID 到订单 ID 的哈希表 map[ProviderID][]ID ,想找出供应商 X 已完成的订单,又该怎么做?
类似的,取供应商 X 的订单 ID 列表和已完成的订单 ID 列表的交集就行了。
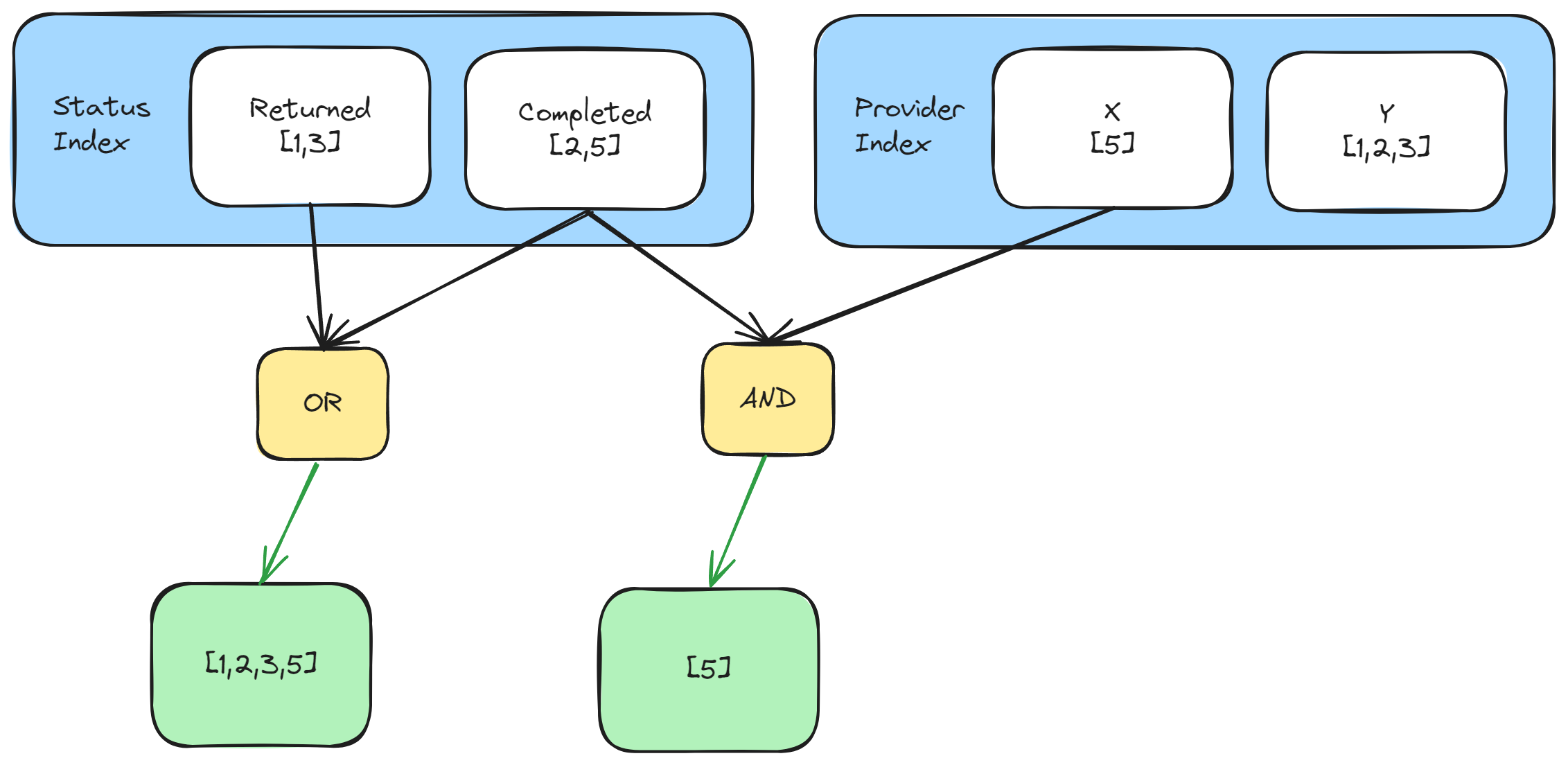
这就是倒排索引实现复杂查询的基本思路:先用索引得到每个筛选条件的倒排列表,再用集合运算组合它们。
加上排序和分页
把倒排索引类比成哈希表,可能会让人觉得它只能用于筛选,做不了排序。
实际上哈希表只是倒排索引的一种实现,需要排序时,可以用其他有序的结构来实现,比如有序数组或搜索树。
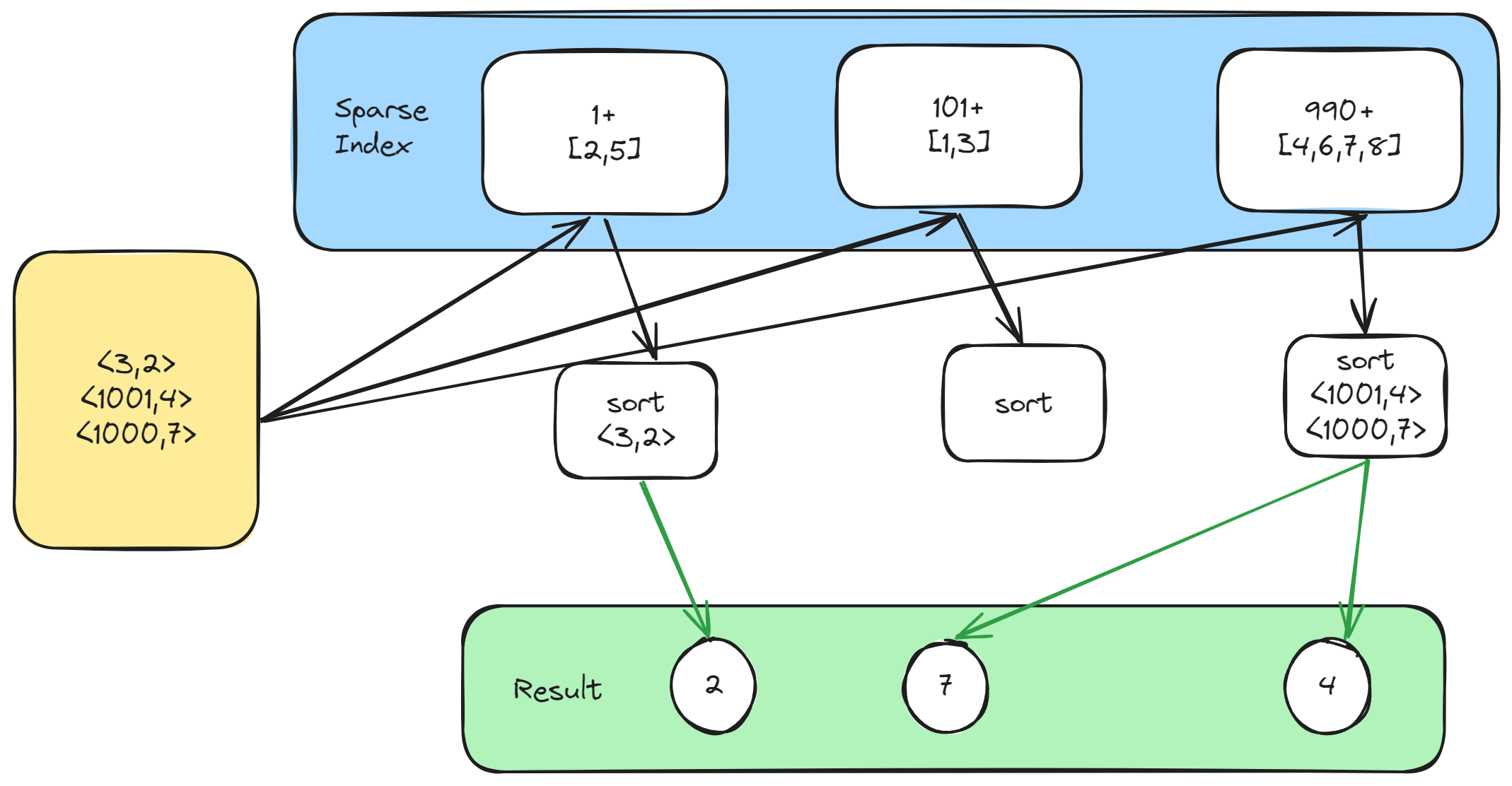
以创建时间为例,我们可以用一个有序数组 []Tuple[Time,[]ID] 来保存订单的创建时间和 ID,作为一个倒排索引。
要把筛选后的订单按创建时间排序时,可以先获取筛选后的倒排列表,然后遍历创建时间的有序数组,逐个取交集,顺序追加,再根据分页大小停止遍历,得到最终结果。
这个算法看起来很简洁,但有性能问题。
最差情况订单的创建时间分布比较平均,而且筛选的订单都在最后一秒,这时它的时间复杂度会是 O(N) ,N 是创建时间的基数,跟订单总数成正比。
应对这种稀疏分布的情况,我们可以把相近创建时间的倒排列表合并,让索引变得稠密。
代价是每次与合并的倒排列表取交集后,还需要再排序一次。
为了减少无用的排序,稀疏索引还要限制倒排列表的大小,理想情况下,需要排序的列表大小等于分页大小。
Postings list 的实现
前面的组合算法,都是基于集合运算,所以倒排列表的实现要支持高效的集合运算。
ElasticSearch 在他们的博客 Frame of Reference and Roaring Bitmaps 中介绍了几种实现,可以概括为压缩列表或位图,两者都可以实现集合运算。
通过性能基准测试,他们确定了一个可以兼顾压缩率和运算效率的位图实现 Roaring Bitmap。
我们下面也会用到它。
实践: 订单筛选系统
Talk is cheap. Show me the code.
我们用 Golang 代码演示如何实现倒排索引,并用它来构建一个订单筛选服务。
服务围绕一个简单的 postgresql 订单表实现查询功能,表包含订单状态、商品 ID、供应商 ID 和创建时间:
1
2
3
4
5
6
7
| CREATE TABLE orders (
id serial PRIMARY KEY,
order_status SMALLINT NOT NULL,
product_id INTEGER NOT NULL,
provider_id INTEGER DEFAULT NULL,
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
|
项目仓库是 https://github.com/KKKIIO/inv-index-demo 。
整个项目分为两个部分:使用索引查询和构建索引。
查询
服务只有一个查询接口,支持根据订单状态、商品、供应商以及它们的组合筛选订单,并按创建时间逆序返回前 N 条。
1
2
3
4
5
6
| type Request struct {
OrderStatusEq *int64
ProductIDEq *int64
ProviderIDFilter *NullableValueFilter[int64]
Limit *int
}
|
这里我们额外支持一种筛选,叫非空筛选,它让我们可以筛选出供应商不为空的订单。
1
2
3
4
5
6
7
8
9
10
| const (
FilterModeEq NullableValueFilterMode = iota
FilterModeNull
FilterModeNotNull
)
type NullableValueFilter[T any] struct {
Mode NullableValueFilterMode
Value T
}
|
实现非空筛选需要我们额外维护一个“全量”索引,它的倒排列表包含所有订单的 ID。
这样就可以用全量集合减去供应商为空的集合,得到供应商不为空的结果。
现在可以确定我们需要的索引了,分别是一个全量索引,三个值索引和一个稀疏索引:
1
2
3
4
5
6
7
| type OrdersSearchService struct {
AllIndexReader *TermIndexReader[int64]
OrderStatusIndexReader *TermIndexReader[int64]
ProductIdIndexReader *TermIndexReader[int64]
ProviderIdIndexReader *TermIndexReader[*int64]
CreateTimeIndexReader *SparseU64IndexReader
}
|
查询流程比较朴实:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| func (s *OrdersSearchService) List(r Request) (*Response, error) {
accBm, err := s.AllIndexReader.Get(0)
if err != nil {
return nil, err
}
if r.OrderStatusEq != nil {
bm, err := s.OrderStatusIndexReader.Get(*r.OrderStatusEq)
if err != nil {
return nil, err
}
accBm.And(bm)
}
if r.ProductIDEq != nil {
bm, err := s.ProductIdIndexReader.Get(*r.ProductIDEq)
if err != nil {
return nil, err
}
accBm.And(bm)
}
if r.ProviderIDFilter != nil {
switch r.ProviderIDFilter.Mode {
case FilterModeEq:
bm, err := s.ProviderIdIndexReader.Get(&r.ProviderIDFilter.Value)
if err != nil {
return nil, err
}
accBm.And(bm)
case FilterModeNull:
bm, err := s.ProviderIdIndexReader.Get(nil)
if err != nil {
return nil, err
}
accBm.And(bm)
case FilterModeNotNull:
bm, err := s.ProviderIdIndexReader.Get(nil)
if err != nil {
return nil, err
}
accBm.AndNot(bm)
}
}
resp := Response{Total: accBm.GetCardinality()}
if (r.Limit != nil && *r.Limit == 0) || resp.Total == 0 {
return &resp, nil
}
resultIds := make([]uint32, 0)
if err := s.CreateTimeIndexReader.Scan(accBm, true, func(sortedIds []index.SortId) bool {
for _, sortId := range sortedIds {
resultIds = append(resultIds, sortId.Id)
if r.Limit != nil && len(resultIds) >= *r.Limit {
return false
}
}
return true
}); err != nil {
return nil, err
}
resp.IDs = resultIds
return &resp, nil
}
|
读取索引的逻辑在对应的 Reader 里。
读取值索引的倒排列表很简单,直接从 KV 存储里取出来就行了:
1
2
3
| func (r *TermIndexReader[T]) Get(fv T) (*roaring.Bitmap, error) {
return r.BmStore.Get(r.Index.GetIndexKey(), r.Index.MakeValueKey(fv))
}
|
排序要遍历稀疏索引,根据分页大小停止,这里用回调函数来实现流式处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| func (r *SparseU64IndexReader) Scan(baseBm *roaring.Bitmap, reverse bool, proc func([]index.SortId) bool) error {
start, end := uint64(0), uint64(0xFFFFFFFFFFFFFFFF)
if reverse {
start, end = end, start
}
indexKey := r.Index.MakeIndexKey()
for start != end {
sortedBms, err := r.BmStore.Scan(indexKey, start, end, reverse, 100)
if err != nil {
return err
}
if len(sortedBms) == 0 {
break
}
start = sortedBms[len(sortedBms)-1].SortKey
if start != end {
if !reverse {
start += 1
} else {
start -= 1
}
}
for _, sortedBm := range sortedBms {
sortedBm.Bitmap.And(baseBm)
if sortedBm.Bitmap.GetCardinality() == 0 {
continue
}
sortedIds, err := index.QuerySortIds(r.FvStore, indexKey, sortedBm.Bitmap)
if err != nil {
return err
}
if reverse {
slices.Reverse(sortedIds)
}
if !proc(sortedIds) {
return nil
}
}
}
return nil
}
|
构建索引
我们希望能实时获取订单数据的变更,构建索引。
项目用 Debezium 这个开源的 CDC 工具,同步 Postgresql 数据库的变更到 Kafka ,服务再从 Kafka 消费变更事件,更新索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| type saramaConsumer struct {
AllIndexWriter *TermIndexWriter[int64]
OrderStatusIndexWriter *TermIndexWriter[int64]
ProductIdIndexWriter *TermIndexWriter[int64]
ProviderIdIndexWriter *TermIndexWriter[*int64]
CreateTimeIndexWriter *SparseU64IndexWriter
}
func (consumer *saramaConsumer) onInsert(order Order) error {
if err := consumer.AllIndexWriter.Add(consumer.BmStore, 0, order.ID); err != nil {
return err
}
if err := consumer.OrderStatusIndexWriter.Add(consumer.BmStore, order.OrderStatus, order.ID); err != nil {
return err
}
if err := consumer.ProductIdIndexWriter.Add(consumer.BmStore, order.ProductID, order.ID); err != nil {
return err
}
if err := consumer.ProviderIdIndexWriter.Add(consumer.BmStore, order.ProviderID, order.ID); err != nil {
return err
}
if err := consumer.CreateTimeIndexWriter.Add(consumer.SortedBmStore, consumer.FvStore, order.CreateTime, order.ID); err != nil {
return err
}
return nil
}
func (consumer *saramaConsumer) onUpdate(before Order, after Order) error {
}
func (consumer *saramaConsumer) onDelete(order Order) error {
}
|
我们把更新索引的逻辑放在对应的 Writer 里。
先看看值索引的更新,它的实现很简单,只需要把 ID 加入或移出倒排列表就行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| func (w *TermIndexWriter[T]) Add(bmStore *store.RedisBmStore, fv T, id uint32) error {
indexKey := w.Index.GetIndexKey()
key := w.Index.MakeValueKey(fv)
bm, err := bmStore.Get(indexKey, key)
if err != nil {
return err
}
bm.Add(id)
if err := bmStore.Set(indexKey, key, bm); err != nil {
return err
}
return nil
}
func (w *TermIndexWriter[T]) Remove(bmStore *store.RedisBmStore, fv T, id uint32) error {
indexKey := w.Index.GetIndexKey()
key := w.Index.MakeValueKey(fv)
bm, err := bmStore.Get(indexKey, key)
if err != nil {
return err
}
bm.Remove(id)
if err := bmStore.Set(indexKey, key, bm); err != nil {
return err
}
return nil
}
func (w *TermIndexWriter[K]) Move(bmStore *store.RedisBmStore, before K, after K, id uint32) error {
if before == after {
return nil
}
if err := w.Remove(bmStore, before, id); err != nil {
return err
}
if err := w.Add(bmStore, after, id); err != nil {
return err
}
return nil
}
|
比较复杂的是稀疏索引的更新。
它需要维护索引的有序性,保存每个 ID 的排序值,还要调整倒排列表的大小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| func (w *SparseU64IndexWriter) Add(bmStore *store.RedisSortKeyBitmapStore, fvStore *store.RedisFvStore, fv uint64, id uint32) error {
fieldKey := w.Index.MakeIndexKey()
floorSortedBm, err := getFloorSortedBm(bmStore, fieldKey, fv)
if err != nil {
return err
}
var updateSortedBms []store.SortKeyBitmap
if floorSortedBm == nil {
updateSortedBms = []store.SortKeyBitmap{{SortKey: fv, Bitmap: roaring.New()}}
} else if floorSortedBm.Bitmap.GetCardinality() < uint64(w.SplitThreshold) {
updateSortedBms = []store.SortKeyBitmap{*floorSortedBm}
} else {
sortIds, err := index.QuerySortIds(fvStore, fieldKey, floorSortedBm.Bitmap)
if err != nil {
return err
}
if sortIds[0].SortKey == sortIds[len(sortIds)-1].SortKey {
updateSortedBms = []store.SortKeyBitmap{*floorSortedBm}
} else {
midKey := sortIds[len(sortIds)/2].SortKey
if midKey == sortIds[len(sortIds)-1].SortKey {
midKey -= 1
}
mid := sort.Search(len(sortIds), func(i int) bool { return sortIds[i].SortKey > midKey })
if mid == 0 {
panic(fmt.Errorf("mid == 0, sortIds=%+v", sortIds))
}
bm1 := floorSortedBm.Bitmap
bm1.Clear()
for _, sortId := range sortIds[:mid] {
bm1.Add(sortId.Id)
}
bm2 := roaring.New()
for _, sortId := range sortIds[mid:] {
bm2.Add(sortId.Id)
}
updateSortedBms = []store.SortKeyBitmap{{SortKey: sortIds[0].SortKey, Bitmap: bm1}, {SortKey: sortIds[mid].SortKey, Bitmap: bm2}}
if updateSortedBms[1].SortKey <= fv {
updateSortedBms[0], updateSortedBms[1] = updateSortedBms[1], updateSortedBms[0]
}
}
}
updateSortedBms[0].Bitmap.Add(id)
if err := bmStore.MSet(fieldKey, updateSortedBms); err != nil {
return err
}
if err := fvStore.Set(fieldKey, id, fv); err != nil {
return err
}
return nil
}
|
总结
倒排索引是一种非常灵活的索引结构,适合用于构建灵活的查询系统。