谁动了我的CPU
文章目录
几年前进了一家 toB 软件公司,主要产品功能都跑在一个大单体 Go 服务里。
一天我们接到一个性能优化任务,客户要求在千万级数据量、50 并发下,接口 90 分位耗时保持 500ms 以下。
当时我只在 ToC 公司工作过,并不觉得这是一个很高的要求,直到去测试环境上体验,发现到处都是接口超时错误。
ToB 复杂软件
ToB 软件要满足不同客户的定制需求,通常会把系统做得大而全。
这个系统更是典型,功能多,配置层级多,还会像 CSS 一样会相互影响。
归根到底也是个正常的 Web 服务,我想。
按经验,服务端性能问题几乎是数据查询慢导致的,排查方向自然是先从数据库 MySQL 慢日志开始。
不知道算不算好事,MySQL 的慢日志在狂刷。
想抓住一条日志来分析,却在代码里搜不到对应 SQL。
“是框架查的数据库“,我担心的事情发生了。
自研框架
这系统有个功能强大、高度灵活的自研查询框架,简称 G。
它对外暴露 GraphQL 接口,对内负责查询数据库。
业务只负责定义“对象”结构,框架会自动根据外部请求里的查询字段、筛选条件,去查询、筛选数据,像是一个魔化版的 Django 。
拿 GraphQL 官方文档例子来说,下面这个查询:
1 | query HeroNameAndFriends($episode: Episode) { |
会先根据 episode 查询出 hero,再根据 hero 查询出 friends,最后返回结果。
强大和灵活的代价是,你几乎不知道这些慢 SQL 是怎么来的,组装 SQL 依赖前面一堆步骤处理后的参数。
没法要求原作者详细解释这个框架,硬啃代码又显然太慢。
我们希望有个快捷的方法,从一堆现象里找到问题。
动态类型、高度并发
为了快,我先用 Go 官方提供的 pprof[1] 工具分析程序。
pprof 可以分析 CPU 使用情况,虽然这不会告诉你数据库查询花了多久,但一些结果集大的查询会因为内存分配频繁,被 pprof 捕捉到调用栈,再被我们观察到。
结果不如人意,调用栈上几乎全是框架 G 的内部函数,它精巧的设计影响了排查工作:
- 框架 G 使用大量 goroutine 并发查询每个字段,导致调用栈丢失了来源函数的信息。
- 框架 G 到处使用
any传递数据,高度复用的查询代码让不同请求的调用栈都惊人地一致。
从 pprof 结果里看不出程序在跑哪块业务流程,在做什么。
求助以前优化过该系统的同事,得知当时也只用 pprof,解决的问题很少。
我们需要探索新方案。
观察系统
我们最大的问题就是不知道程序在做什么,因此提升可观察性 Observability 是关键。
观察耗时的工具可分为指标 Metrics、日志 Logging、链路追踪 Tracing。
而链路追踪能记录一个请求在系统中的执行过程,无论执行是串行还是并发,系统是单体还是分布式,这非常符合我们的需求。
go 主流的 tracing 方案是侵入式的,需要修改代码埋点。
我申请了一天时间,用 gls 和改 vendor 等旁门左道在数据库操作等关键区域埋点。
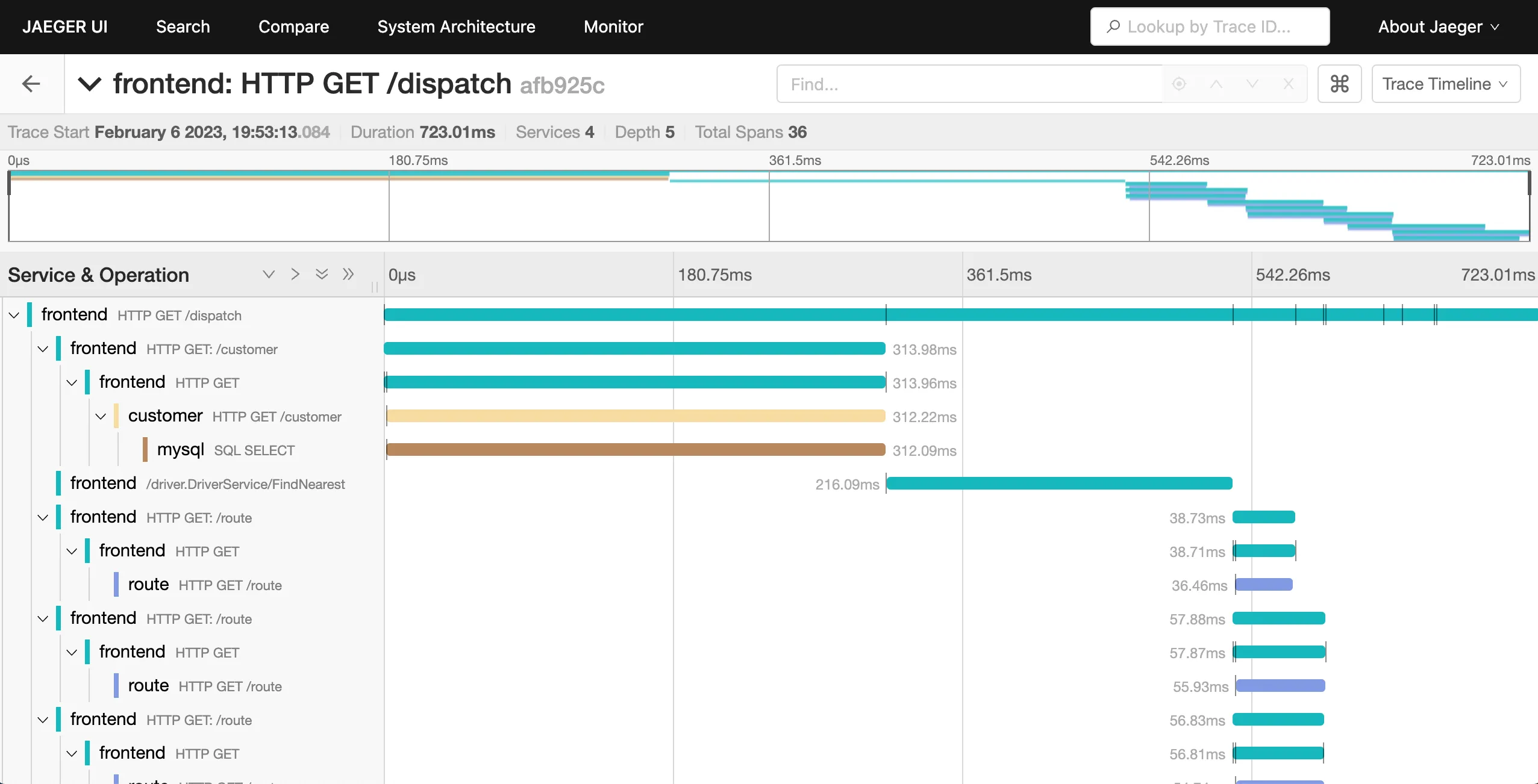
结果还算满意,在链路图里能看到一次请求下很多动作 Span 的耗时、先后次序。
在链路追踪的帮助下,我们定位到了很多问题,下面举几个有趣的例子。
阳光猛烈,万物显形
锁,缓存和读降级
在压测下,有时会出现一段时间内不少接口的耗时飙升到 5 秒以上的情况。
在这些请求的链路图里,都有一段 5 秒的 Span,底下没有任何数据库查询。
顺藤摸瓜,我在底层找到了一个锁,它用于管理一个粒度很粗的缓存。
请求每次都要从缓存拿几百万条数据,一旦缓存过期,就得拿着锁,花几十秒去查数据库。
可能这个缓存性能问题太明显,之前的人又给它加上读降级机制:当缓存过期时,先尝试抢锁 5 秒,如果抢不到,就返回过期数据。
这些机制不仅没解决性能问题,反而让排查变得复杂,我们赶紧去掉了它们,并优化了缓存粒度。
悲观的 Redis 锁
当我们把并发从 50 提高到 100 时,一些写接口耗时从几百毫秒飙升到几秒以上。
链路图可以看到不少重复的 Redis SETNX 操作,明显是在实现锁。
SETNX操作间隔 200ms ,也就是说一旦抢锁失败就会等 200ms 再试一次。
一旦锁冲突多了,等待次数就变多,耗时也会变长。
程序用 Redis 锁的地方挺多,我们去掉了一些不必要的加锁操作,也有用 lua 脚本实现原子操作代替了锁。
Shlemiel 油漆算法[2]
如果不是亲眼所见,我很难相信纯内存操作能耗时十几秒。
有一段很长的链路下面没有任何 IO 和锁操作。
在我用二分法埋点排除各种嫌疑后,才发现罪魁祸首是一个看似简朴的内存筛选操作。
它的实现是把不符合条件的元素从数组中删除。
问题是,这里把删除一个元素实现成了 O(N) 算法,那删除 M 个元素就是 O(M*N) 的复杂度。
当数量比较大时,这个操作就拖慢了整个请求。
也许做算法题是有用的 😈。
二八定律
难道所有性能问题都可以通过“仔细观察”解决吗?
当然不是,例如我在动手写查询引擎提到的复杂查询,即使知道执行流程,也很难通过调整数据库索引来优化每个场景的性能,得改变算法(如上索引服务 ElasticSearch)才能整体解决问题。
然而超过 80% 的性能问题,都可以在“仔细观察”后轻松解决。
就像处理 BUG,多数精力都用在取得那条关键日志。
优化性能则是需要观察程序在做什么,然后把可以不做/少做的事情去掉。
对 pprof 还不了解的推荐看 Go 官方博客 Profiling Go Programs ↩︎
原文作者: KKKIIO
原文链接: https://kkkiio.github.io/perf-monolithic-software/
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议